Go 语言踩坑记——panic 与 recover
[作者简介] 易乐天,小米信息技术部海外商城组
题记
Go 语言自发布以来,一直以高性能、高并发著称。因为标准库提供了 http 包,即使刚学不久的程序员,也能轻松写出 http 服务程序。
不过,任何事情都有两面性。一门语言,有它值得骄傲的有点,也必定隐藏了不少坑。新手若不知道这些坑,很容易就会掉进坑里。《 Go 语言踩坑记》系列博文将以 Go 语言中的 panic 与 recover 开头,给大家介绍笔者踩过的各种坑,以及填坑方法。
初识 panic 和 recover
panicpanic这个词,在英语中具有恐慌、恐慌的等意思。从字面意思理解的话,在 Go 语言中,代表极其严重的问题,程序员最害怕出现的问题。一旦出现,就意味着程序的结束并退出。Go 语言中panic关键字主要用于主动抛出异常,类似java等语言中的throw关键字。recoverrecover这个词,在英语中具有恢复、复原等意思。从字面意思理解的话,在 Go 语言中,代表将程序状态从严重的错误中恢复到正常状态。Go 语言中recover关键字主要用于捕获异常,让程序回到正常状态,类似java等语言中的try ... catch。
笔者有过 6 年 linux 系统 C 语言开发经历。C 语言中没有异常捕获的概念,没有 try ... catch ,也没有 panic 和 recover 。不过,万变不离其宗,异常与 if error then return 方式的差别,主要体现在函数调用栈的深度上。如下图:
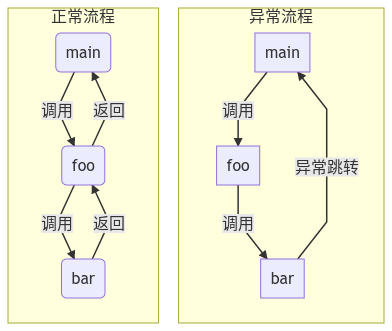
正常逻辑下的函数调用栈,是逐个回溯的,而异常捕获可以理解为:程序调用栈的长距离跳转。这点在 C 语言里,是通过 setjump 和 longjump 这两个函数来实现的。
try catch 、 recover 、setjump 等机制会将程序当前状态(主要是 cpu 的栈指针寄存器 sp 和程序计数器 pc , Go 的 recover 是依赖 defer 来维护 sp 和 pc )保存到一个与 throw、panic、longjump共享的内存里。当有异常的时候,从该内存中提取之前保存的 sp 和 pc 寄存器值,直接将函数栈调回到 sp 指向的位置,并执行 ip 寄存器指向的下一条指令,将程序从异常状态中恢复到正常状态。
深入 panic 和 recover
源码
panic 和 recover 的源码在 Go 源码的 src/runtime/panic.go 里,名为 gopanic 和 gorecover 的函数。
1 | // gopanic 的代码,在 src/runtime/panic.go 第 454 行 |
1 | // gorecover 的代码,在 src/runtime/panic.go 第 585 行 |
从函数代码中我们可以看到 panic 内部主要流程是这样:
- 获取当前调用者所在的
g,也就是goroutine - 遍历并执行
g中的defer函数 - 如果
defer函数中有调用recover,并发现已经发生了panic,则将panic标记为recovered - 在遍历
defer的过程中,如果发现已经被标记为recovered,则提取出该defer的 sp 与 pc,保存在g的两个状态码字段中。 调用
runtime.mcall切到m->g0并跳转到recovery函数,将前面获取的g作为参数传给recovery函数。runtime.mcall的代码在 go 源码的src/runtime/asm_xxx.s中,xxx是平台类型,如amd64。代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36// src/runtime/asm_amd64.s 第 274 行
// func mcall(fn func(*g))
// Switch to m->g0's stack, call fn(g).
// Fn must never return. It should gogo(&g->sched)
// to keep running g.
TEXT runtime·mcall(SB), NOSPLIT, $0-8
MOVQ fn+0(FP), DI
get_tls(CX)
MOVQ g(CX), AX // save state in g->sched
MOVQ 0(SP), BX // caller's PC
MOVQ BX, (g_sched+gobuf_pc)(AX)
LEAQ fn+0(FP), BX // caller's SP
MOVQ BX, (g_sched+gobuf_sp)(AX)
MOVQ AX, (g_sched+gobuf_g)(AX)
MOVQ BP, (g_sched+gobuf_bp)(AX)
// switch to m->g0 & its stack, call fn
MOVQ g(CX), BX
MOVQ g_m(BX), BX
MOVQ m_g0(BX), SI
CMPQ SI, AX // if g == m->g0 call badmcall
JNE 3(PC)
MOVQ $runtime·badmcall(SB), AX
JMP AX
MOVQ SI, g(CX) // g = m->g0
MOVQ (g_sched+gobuf_sp)(SI), SP // sp = m->g0->sched.sp
PUSHQ AX
MOVQ DI, DX
MOVQ 0(DI), DI
CALL DI
POPQ AX
MOVQ $runtime·badmcall2(SB), AX
JMP AX
RET这里之所以要切到
m->g0,主要是因为 Go 的runtime环境是有自己的堆栈和goroutine,而recovery是在runtime环境下执行的,所以要先调度到m->g0来执行recovery函数。recovery函数中,利用g中的两个状态码回溯栈指针 sp 并恢复程序计数器 pc 到调度器中,并调用gogo重新调度g,将g恢复到调用recover函数的位置, goroutine 继续执行。
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// gorecover 的代码,在 src/runtime/panic.go 第 637 行
// Unwind the stack after a deferred function calls recover
// after a panic. Then arrange to continue running as though
// the caller of the deferred function returned normally.
func recovery(gp *g) {
// Info about defer passed in G struct.
sp := gp.sigcode0
pc := gp.sigcode1
// d's arguments need to be in the stack.
if sp != 0 && (sp < gp.stack.lo || gp.stack.hi < sp) {
print("recover: ", hex(sp), " not in [", hex(gp.stack.lo), ", ", hex(gp.stack.hi), "]\n")
throw("bad recovery")
}
// Make the deferproc for this d return again,
// this time returning 1. The calling function will
// jump to the standard return epilogue.
gp.sched.sp = sp
gp.sched.pc = pc
gp.sched.lr = 0
gp.sched.ret = 1
gogo(&gp.sched)
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// src/runtime/asm_amd64.s 第 274 行
// func gogo(buf *gobuf)
// restore state from Gobuf; longjmp
TEXT runtime·gogo(SB), NOSPLIT, $16-8
MOVQ buf+0(FP), BX // gobuf
MOVQ gobuf_g(BX), DX
MOVQ 0(DX), CX // make sure g != nil
get_tls(CX)
MOVQ DX, g(CX)
MOVQ gobuf_sp(BX), SP // restore SP
MOVQ gobuf_ret(BX), AX
MOVQ gobuf_ctxt(BX), DX
MOVQ gobuf_bp(BX), BP
MOVQ $0, gobuf_sp(BX) // clear to help garbage collector
MOVQ $0, gobuf_ret(BX)
MOVQ $0, gobuf_ctxt(BX)
MOVQ $0, gobuf_bp(BX)
MOVQ gobuf_pc(BX), BX
JMP BX
以上便是 Go 底层处理异常的流程,精简为三步便是:
defer函数中调用recover- 触发
panic并切到runtime环境获取在defer中调用了recover的g的 sp 和 pc - 恢复到
defer中recover后面的处理逻辑
都有哪些坑
前面提到,panic 函数主要用于主动触发异常。我们在实现业务代码的时候,在程序启动阶段,如果资源初始化出错,可以主动调用 panic 立即结束程序。对于新手来说,这没什么问题,很容易做到。
但是,现实往往是残酷的—— Go 的 runtime 代码中很多地方都调用了 panic 函数,对于不了解 Go 底层实现的新人来说,这无疑是挖了一堆深坑。如果不熟悉这些坑,是不可能写出健壮的 Go 代码。
接下来,笔者给大家细数下都有哪些坑。
这个比较好理解,对于静态类型语言,数组下标越界是致命错误。如下代码可以验证:
1 | package main |
输出:
1 | runtime error: index out of range |
因为代码中用了 recover ,程序得以恢复,输出 exit。
如果将 recover 那几行注释掉,将会输出如下日志:
1 | panic: runtime error: index out of range |
对于有 c/c++ 开发经验的人来说,这个很好理解。但对于没用过指针的新手来说,这是最常见的一类错误。
如下代码可以验证:
1 | package main |
输出:
1 | runtime error: invalid memory address or nil pointer dereference |
如果将 recover 那几行代码注释掉,则会输出:
1 | panic: runtime error: invalid memory address or nil pointer dereference |
这也是刚学用 chan 的新手容易犯的错误。如下代码可以验证:
1 | package main |
输出:
1 | send on closed channel |
如果注释掉 recover ,将输出:
1 | panic: send on closed channel |
源码处理逻辑在 src/runtime/chan.go 的 chansend 函数中,如下:
1 | // src/runtime/chan.go 第 269 行 |
对于刚学并发编程的同学来说,并发读写 map 也是很容易遇到的问题。如下代码可以验证:
1 | package main |
输出:
1 | fatal error: concurrent map read and map write |
细心的朋友不难发现,输出日志里没有出现我们在程序末尾打印的 exit,而是直接将调用栈打印出来了。查看 src/runtime/map.go 中的代码不难发现这几行:
1 | if h.flags&hashWriting != 0 { |
与前面提到的几种情况不同,runtime 中调用 throw 函数抛出的异常是无法在业务代码中通过 recover 捕获的,这点最为致命。所以,对于并发读写 map 的地方,应该对 map 加锁。
在使用类型断言对 interface 进行类型转换的时候也容易一不小心踩坑,而且这个坑是即使用 interface 有一段时间的人也容易忽略的问题。如下代码可以验证:
1 | package main |
输出:
1 | interface conversion: interface {} is string, not []string |
源码在 src/runtime/iface.go 中,如下两个函数:
1 | // panicdottypeE is called when doing an e.(T) conversion and the conversion fails. |
更多的 panic
前面提到的只是基本语法中常遇到的几种 panic 场景,Go 标准库中有更多使用 panic 的地方,大家可以在源码中搜索 panic( 找到调用的地方,以免后续用标准库函数的时候踩坑。
限于篇幅,本文暂不介绍填坑技巧,后面再开其他篇幅逐个介绍。感谢阅读!
下回预告
Go 语言踩坑记之 channel 与 goroutine。
作者
易乐天,小米信息技术部海外商城组
招聘
信息部是小米公司整体系统规划建设的核心部门,支撑公司国内外的线上线下销售服务体系、供应链体系、ERP 体系、内网 OA 体系、数据决策体系等精细化管控的执行落地工作,服务小米内部所有的业务部门以及 40 家生态链公司。
同时部门承担大数据基础平台研发和微服务体系建设落,语言涉及 Java、Go,长年虚位以待对大数据处理、大型电商后端系统、微服务落地有深入理解和实践的各路英雄。
欢迎投递简历:jin.zhang(a)xiaomi.com(武汉)
扫描二维码,分享此文章